🚀 Getting Started
📋 API Configuration
VideoLingo requires an LLM and TTS(optional). For the best quality, use claude-sonnet-4.6 or gpt-5.4 with Azure TTS. Alternatively, for a fully local setup with no API key needed, use Ollama for the LLM and Edge TTS for dubbing. In this case, set max_workers to 1 and summary_length to a low value like 2000 in config.yaml.
1. Get API_KEY for LLM:
| Recommended Model | Vendor | Quality | Cost-efficiency |
|---|---|---|---|
| claude-sonnet-4-6 | Anthropic (opens in a new tab) | 🤩 | ⭐⭐⭐ |
| claude-opus-4-6 | Anthropic (opens in a new tab) | 🏆 | ⭐⭐ |
| gpt-5.2 | OpenAI (opens in a new tab) | 🤩 | ⭐⭐⭐ |
| gemini-3-flash | Google (opens in a new tab) | 😃 | ⭐⭐⭐⭐⭐ |
| gemini-3.1-pro | Google (opens in a new tab) | 🤩 | ⭐⭐⭐ |
| minimax-m2.5 | MiniMax (opens in a new tab) | 😃 | ⭐⭐⭐⭐⭐ |
| kimi-k2.5 | Moonshot AI (opens in a new tab) | 😃 | ⭐⭐⭐⭐ |
| deepseek-v3 | DeepSeek (opens in a new tab) | 🥳 | ⭐⭐⭐⭐ |
| qwen3-32b | Ollama (opens in a new tab) self-hosted | 😃 | ♾️ Free |
Tip: Model pricing changes frequently. Check each vendor's website for current rates. models.dev (opens in a new tab) offers cross-vendor price and capability comparison.
API proxy: If you cannot access overseas APIs directly, OpenRouter (opens in a new tab) is recommended (supports all models above, unified OpenAI-format API, pay-per-use with no monthly fee).
Note: Supports OpenAI format, you can try different models at your risk. However, the process involves multi-step reasoning chains and complex JSON formats, not recommended to use models smaller than 30B.
2. TTS API
VideoLingo provides multiple TTS integration methods. Here's a comparison (skip if only using translation without dubbing)
| TTS Solution | Provider | Pros | Cons | Chinese Effect | Non-Chinese Effect |
|---|---|---|---|---|---|
| 🔊 Azure TTS ⭐ | 302AI (opens in a new tab) | Natural effect | Limited emotions | 🤩 | 😃 |
| 🎙️ OpenAI TTS | 302AI (opens in a new tab) | Realistic emotions | Chinese sounds foreign | 😕 | 🤩 |
| 🎤 Fish TTS | 302AI (opens in a new tab) | Authentic native | Limited official models | 🤩 | 😂 |
| 🎙️ SiliconFlow FishTTS | SiliconFlow (opens in a new tab) | Voice Clone | Unstable cloning effect | 😃 | 😃 |
| 🗣 Edge TTS | Local | Completely free | Average effect | 😐 | 😐 |
| 🗣️ GPT-SoVITS | Local | Best voice cloning | Only supports Chinese/English, requires local inference, complex setup | 🏆 | 🚫 |
- For SiliconFlow FishTTS, get key from SiliconFlow (opens in a new tab), note that cloning feature requires paid credits;
- For OpenAI TTS, Azure TTS, and Fish TTS, use 302AI (opens in a new tab) - one API key provides access to all three services
Wanna use your own TTS? Modify in
core/all_tts_functions/custom_tts.py!
SiliconFlow FishTTS Tutorial
Currently supports 3 modes:
preset: Uses fixed voice, can preview on Official Playground (opens in a new tab), default isanna.clone(stable): Corresponds to fishtts api'scustom, uses voice from uploaded audio, automatically samples first 10 seconds of video for voice, better voice consistency.clone(dynamic): Corresponds to fishtts api'sdynamic, uses each sentence as reference audio during TTS, may have inconsistent voice but better effect.
How to choose OpenAI voices?
Voice list can be found on the official website (opens in a new tab), such as alloy, echo, nova, etc. Modify openai_tts.voice in config.yaml.
How to choose Azure voices?
Recommended to try voices in the online demo (opens in a new tab). You can find the voice code in the code on the right, e.g. zh-CN-XiaoxiaoMultilingualNeural
How to choose Fish TTS voices?
Go to the official website (opens in a new tab) to listen and choose voices. Find the voice code in the URL, e.g. Dingzhen is 54a5170264694bfc8e9ad98df7bd89c3. Popular voices are already added in config.yaml. To use other voices, modify the fish_tts.character_id_dict dictionary in config.yaml.
GPT-SoVITS-v2 Tutorial
-
Check requirements and download the package from official Yuque docs (opens in a new tab).
-
Place
GPT-SoVITS-v2-xxxandVideoLingoin the same directory. Note they should be parallel folders. -
Choose one of the following ways to configure the model:
a. Self-trained model:
- After training,
tts_infer.yamlunderGPT-SoVITS-v2-xxx\GPT_SoVITS\configswill have your model path auto-filled. Copy and rename it toyour_preferred_english_character_name.yaml - In the same directory as the
yamlfile, place reference audio namedyour_preferred_english_character_name_reference_audio_text.wavor.mp3, e.g.Huanyuv2_Hello, this is a test audio.wav - In VideoLingo's sidebar, set
GPT-SoVITS Charactertoyour_preferred_english_character_name.
b. Use pre-trained model:
- Download my model from here (opens in a new tab), extract and overwrite to
GPT-SoVITS-v2-xxx. - Set
GPT-SoVITS CharactertoHuanyuv2.
c. Use other trained models:
-
Place
xxx.ckptinGPT_weights_v2folder andxxx.pthinSoVITS_weights_v2folder. -
Following method a, rename
tts_infer.yamland modifyt2s_weights_pathandvits_weights_pathundercustomto point to your models, e.g.:# Example config for method b: t2s_weights_path: GPT_weights_v2/Huanyu_v2-e10.ckpt version: v2 vits_weights_path: SoVITS_weights_v2/Huanyu_v2_e10_s150.pth -
Following method a, place reference audio in the same directory as the
yamlfile, namedyour_preferred_english_character_name_reference_audio_text.wavor.mp3, e.g.Huanyuv2_Hello, this is a test audio.wav. The program will auto-detect and use it. -
⚠️ Warning: Please use English for
character_nameto avoid errors.reference_audio_textcan be in Chinese. Currently in beta, may produce errors.
# Expected directory structure: . ├── VideoLingo │ └── ... └── GPT-SoVITS-v2-xxx ├── GPT_SoVITS │ └── configs │ ├── tts_infer.yaml │ ├── your_preferred_english_character_name.yaml │ └── your_preferred_english_character_name_reference_audio_text.wav ├── GPT_weights_v2 │ └── [your GPT model file] └── SoVITS_weights_v2 └── [your SoVITS model file] - After training,
After configuration, select Reference Audio Mode in the sidebar (see Yuque docs for details). During dubbing, VideoLingo will automatically open GPT-SoVITS inference API port in the command line, which can be closed manually after completion. Note that stability depends on the base model chosen.
🛠️ Quick Start
VideoLingo supports Windows, macOS and Linux systems, and can run on CPU or GPU.
Note: To use NVIDIA GPU acceleration on Windows, please complete the following steps first:
- Install CUDA Toolkit 12.6 (opens in a new tab) or newer (12.8 / 12.9 / 13.x all work — the install script auto-adapts)
- Install CUDNN 9.3.0 (opens in a new tab)
- Add
C:\Program Files\NVIDIA\CUDNN\v9.3\bin\12.6to your system PATH- Restart your computer
⚠️ Pitfall: The install script uses
nvidia-smito detect your driver's CUDA version and auto-selects the best PyTorch wheel (cu129 / cu128 / cu126). For RTX 50 series (Blackwell) GPUs, cu129 wheels with sm_100 kernels are selected automatically. Do NOT manually install cu130/cu131 PyTorch — this causes ctranslate2 to fail withcublas64_12.dll not found.
Note: FFmpeg is required. Please install it via package managers:
- Windows:
choco install ffmpeg(via Chocolatey (opens in a new tab))- macOS:
brew install ffmpeg(via Homebrew (opens in a new tab))- Linux:
sudo apt install ffmpeg(Debian/Ubuntu) orsudo dnf install ffmpeg(Fedora)⚠️ Pitfall: Do NOT use conda-forge ffmpeg (it lacks the libmp3lame encoder). Use the system package manager to install a full build.
Option A: Using uv (Recommended)
uv (opens in a new tab) is a fast Python package manager that automatically downloads the correct Python version and creates an isolated environment. No need to install Python or Anaconda yourself. (~30 MB vs ~4 GB for Anaconda, 10-100x faster package installs.)
-
Clone the project:
git clone https://github.com/Huanshere/VideoLingo.git cd VideoLingo -
One-command setup (installs uv + Python 3.10 + all dependencies):
python setup_env.py⚠️ Install order matters:
install.py(called automatically bysetup_env.py) installs dependencies in the correct order: PyTorch first (locks CUDA version), then demucs with--no-deps(prevents torchaudio downgrade), then the rest. Do not rearrange manually. -
🎉 Launch Streamlit app:
.venv\Scripts\streamlit run st.py # Windows .venv/bin/streamlit run st.py # macOS / LinuxOr double-click
OneKeyStart.baton Windows. -
Set key in sidebar of popup webpage and start using~
Option B: Using Conda
⚠️ Not recommended. This method will not be maintained going forward. Please use uv (Option A) above.
Click to expand Conda installation steps
Before installing VideoLingo, ensure you have installed Git and Anaconda.
-
Clone the project:
git clone https://github.com/Huanshere/VideoLingo.git cd VideoLingo -
Create and activate virtual environment (must be python=3.10.0):
conda create -n videolingo python=3.10.0 -y conda activate videolingo⚠️ Pitfall: Make sure pip is using the conda env's site-packages. On Windows, if the
site-packagesdirectory is not writable (e.g. underC:\ProgramData\anaconda3\), pip silently installs to the user directory instead. If this happens, run the terminal as administrator. -
Run installation script:
python install.py⚠️ Install order matters:
install.pyinstalls dependencies in the correct order: PyTorch first (locks CUDA version), then demucs with--no-deps(prevents torchaudio downgrade), then the rest. Do not rearrange manually. -
🎉 Launch Streamlit app by running the command or double-clicking
OneKeyStart.bat:streamlit run st.py -
Set key in sidebar of popup webpage and start using~
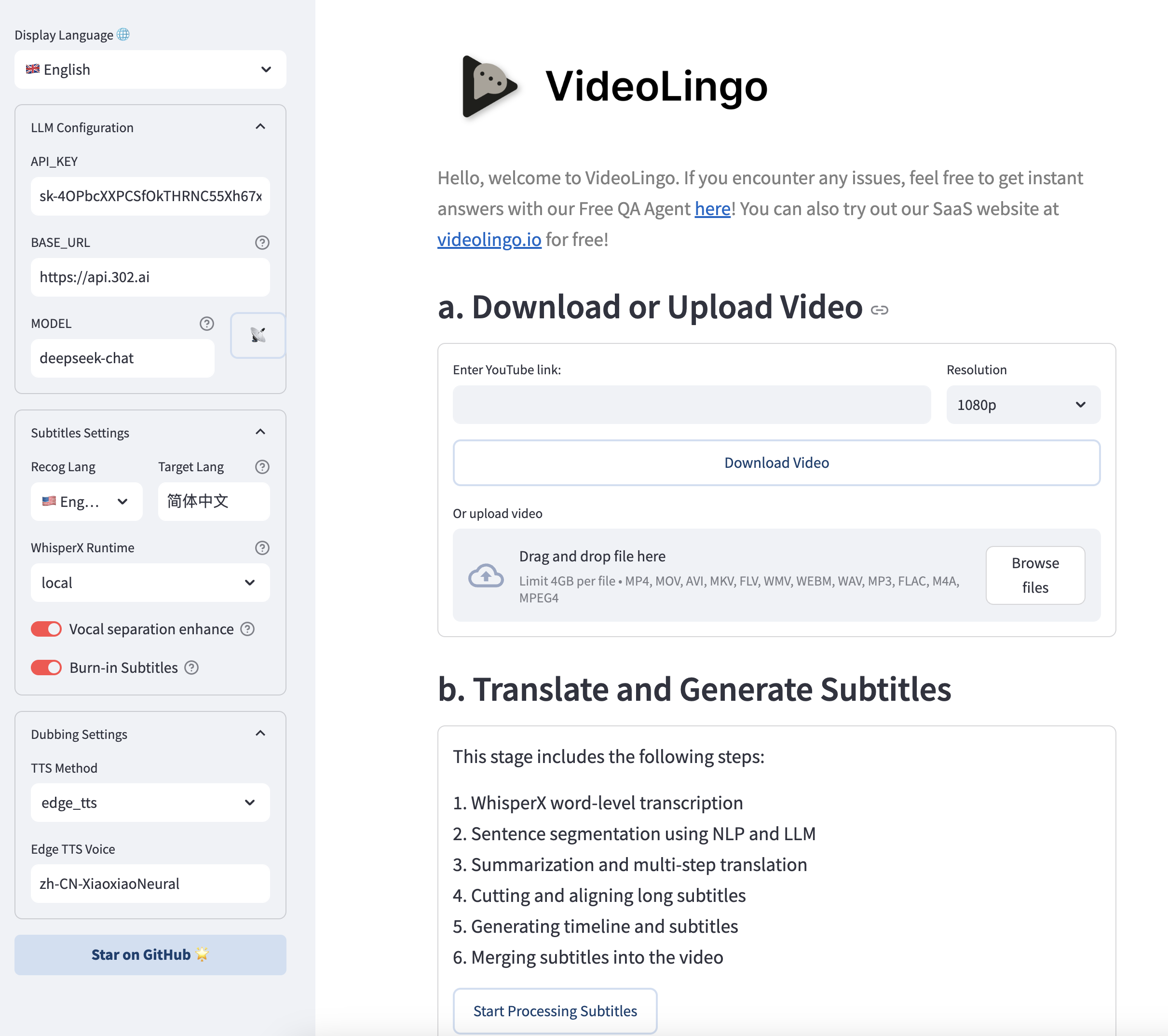
- (Optional) More settings can be manually modified in
config.yaml, watch command line output during operation. To use custom terms, add them tocustom_terms.xlsxbefore processing, e.g.Baguette | French bread | Not just any bread!.
Need help? Our AI Assistant (opens in a new tab) is here to guide you through any issues!
🏭 Batch Mode (beta)
Note: This section is still in early development and may have limited functionality
🚨 Common Errors & Pitfalls
-
'All array must be of the same length' or 'Key Error' during translation:
- Reason 1: Weaker models have poor JSON format compliance causing response parsing errors.
- Reason 2: LLM may refuse to translate sensitive content.
Solution: Check
responseandmsgfields inoutput/gpt_log/error.json, delete theoutput/gpt_logfolder and retry.
-
'Retry Failed', 'SSL', 'Connection', 'Timeout': Usually network issues. Solution: Users in mainland China please switch network nodes and retry.
-
local_files_only=True: Model download failure due to network issues, need to verify network can ping
huggingface.co. -
cublas64_12.dll not found: Installed CUDA 13.x and used cu130/cu131 PyTorch wheels. Solution: Must use cu129, cu128, or cu126 wheels (install.pyhandles this automatically vianvidia-smidetection) because ctranslate2 only supports CUDA 12. Re-runpython install.py. -
Whisper model loading segfaults silently: ctranslate2 version mismatches cuDNN version. Solution: Ensure
ctranslate2>=4.5.0(supports cuDNN 9, which PyTorch 2.6+ ships with). -
RuntimeError: Weights only load failed: PyTorch ≥2.6 changedtorch.loaddefault behavior. Solution: Already fixed via monkey-patch inwhisperX_local.py. If you see this, your code is not up to date. -
WhisperX transcription hangs in Streamlit (CPU/GPU idle):
librosa.load()deadlocks in Streamlit's non-main thread. Solution: Already fixed by replacing withwhisperx.audio.load_audio()(ffmpeg subprocess). If you see this, your code is not up to date. -
spacy
Can't find model 'xx_core_web_md'(but pip says installed): pip installed the model to user directory instead of conda env. Solution: Run terminal as administrator, or manually install with conda env's python:python -m pip install xx-core-web-md --no-user --force-reinstall --no-deps -
torchaudio version drops to 1.x or 2.1.x after pip install: demucs's
torchaudio<2.2constraint causes downgrade. Solution: Neverpip install demucsdirectly — must use--no-deps.install.pyhandles this correctly.